«Машинное чтение» цифровых и не только индикаторов без ИИ и нейронок на Python - «Умные Решения»
- Finch
- 09-фев-2024, 12:51
- 0 комментариев
- 2 731 просмотров

В этой статье рассмотрим простой алгоритм считывания, обработки и распознавания значений цифровых индикаторов из массива фотографий с показаниями приборов.
Не будет машинного обучения, нейросетей, а для распознавания будем применять только библиотеки Python для работы с изображениями.
Требуется собрать и обработать показания приборов с цифровыми индикаторами. Для эксперимента будем использовать подручные бытовые датчики температуры, влажности и содержания CO².
Подготовим коллекцию изображений с нашей «лабораторной установки» любым приложением с функцией таймлапс. Интервал между снимками подбираем так, чтобы не пропустить изменение показателя в 2–5%.
«Установка» может выглядеть следующим образом. Размещаем в одном кадре несколько приборов для измерения показателей воздуха в помещении. В настройках таймлапс приложения укажем интервал 1 минута, длительность 2 часа, размера кадра 640×480px будет достаточно. После обработки изображений сведем данные в таблицу и оценим расхождения в показаниях приборов на графиках.
Итак приступим.
Определим следующие требования к обработчику изображений:
распознаваться должны значения независимо от наклона камеры по отношению к индикатору;
чтобы устранить этап предварительной обработки изображений такие характеристики, как контраст, цветность, яркость изображения не должны оказывать значительного влияния на распознавание;
должна быть возможность простой настройки для выборки зон на изображении, где расположены индикаторы и зон элементов числового индикатора.
Для предварительной разметки размещения индикаторов на снимке подойдет любой файл из коллекции таймлапс изображений.
Код для разметки датчиков на изображении:
# размечаем области с индикаторами
import glob
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
from matplotlib.patches import Rectangle
from scipy import ndimage
# [id, top, bottom, width, height, rotation, description]
indicator_areas = [
[0, 176, 134, 22, 14, 0, "фон"],
[1, 216, 134, 81, 29, 0, "1_CO2"],
[2, 234, 169, 18, 10, 0, "1_Temp"],
[3, 277, 167, 20, 12, 0, "1_Hum"],
[4, 240, 212, 38, 35, -3, "2_Temp"],
[5, 283, 211, 24, 20, -4, "2_Hum"],
[6, 418, 106, 19, 12, 0, "3_Temp"],
[7, 418, 115, 19, 19, -5, "3_Hum"],
[8, 413, 130, 19, 19, -3, "3_CO2"],
[9, 390, 293, 31, 25, -5, "4_Temp"],
[10, 393, 328, 31, 25, -5, "4_Hum"],
]
_fmask = r"src/20240131/2024.01.31_11.14.27/*.jpg" # расположение снимков
image_files = glob.glob( _fmask , recursive=True )
fig, ax = plt.subplots(1, 1, figsize=(10, 5))
_img = mpimg.imread(image_files[1]) # для разметки берем любой файл
_img = ndimage.rotate(_img, 90, reshape=True ) # ориентируем изображение
for ii, s in enumerate(indicator_areas):
id, x, y, w, h, a, n = s
ax.add_patch(
Rectangle((x, y), w, h, edgecolor="#f00", facecolor="blue", fill=False, lw=1)
)
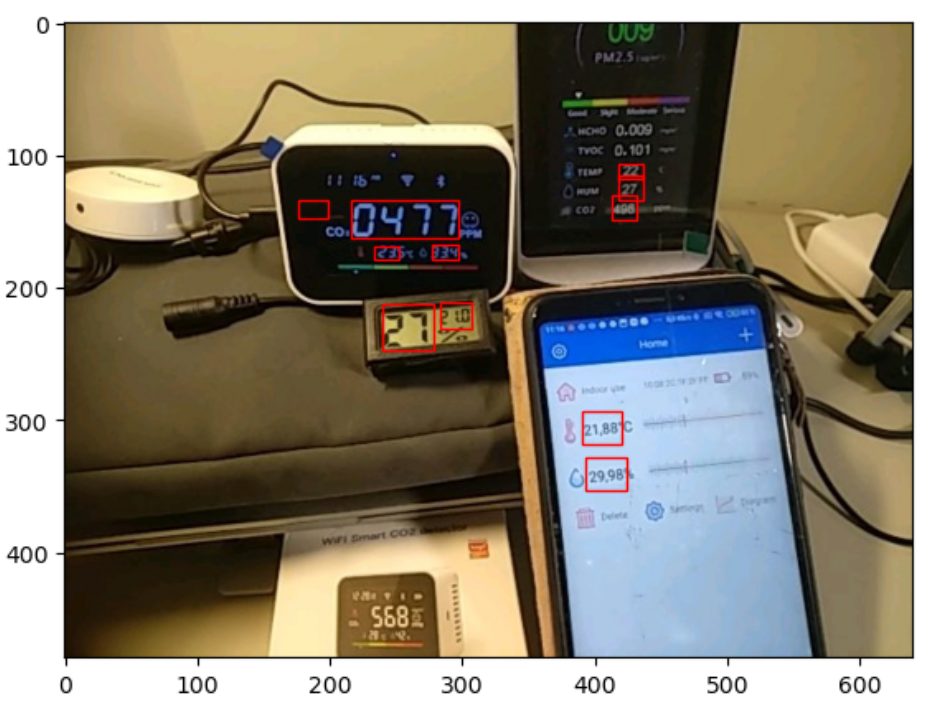
ax.imshow(_img)Немного придется поколдовать над настройкой областей indicator_areas, но в итоге получаем следующий результат:
Чтобы убедиться, что зоны определены корректно, соберем изображения индикаторов в одну таблицу.
# отрисовка значений индикторов в сводной таблице
import glob
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import scipy.ndimage as ndimage
images = []
image_files = glob.glob(r'src202401312024.01.31_11.14.27*.jpg')
for f in image_files[:5]:
_img = mpimg.imread(f)
_img = ndimage.rotate(_img, 90, reshape=True)
images.append(_img)
#
[id, top, bottom, left, rigth, rotation, desctiption]
indicator_areas = [
[0,176,134,22,14,0, "фон"],
[1,216,134,81,29,0, "1_CO2"],
[2,234,169,18,10,0, "1_Temp"],
[3,277,167,20,12,0, "1_Hum"],
[4,240,212,38,35,-3, "2_Temp"],
[5,283,211,24,20,-4, "2_Hum"],
[6,418,106,19,12,0,"3_Temp"],
[7,418,115,19,19,-5,"3_Hum"],
[8,413,130,19,19,-3,"3_CO2"],
[9,390,293,31,25,-5,"4_Temp"],
[10,393,328,31,25,-5,"4_Hum"],
]
n_cols = len(indicator_areas)
n_img = len(images)
fig, axs = plt.subplots(nrows=len(images), ncols=n_cols+1, figsize=(8, int(n_img/1.5)))
plt.setp(plt.gcf().get_axes(), xticks=[], yticks=[]);
plt.subplots_adjust( top=0.7,bottom=0, wspace=0, hspace=0.5)
for i, image in enumerate(images):
for ii, ia in enumerate(indicator_areas):
n,x,y,w,h,a,n = ia
# ID, x,y, width, height, rotation angle
_image = image[y:y+h,x:x+w] # ? Numpy за такую возможность выборки областей
if a != 0:
_image = ndimage.rotate(_image, a, reshape=True)
_image = _image[6:-3,1:-2] # немного подрезаем области с поворотом
# вывод комментария для контроля, что разметка выполна верно
axs[i,ii].text(0,-2, n, **{"color":'#f00', "size":9 })
if(ii == 0 ): axs[i,ii].text(10,8, i, color='#ff0')
axs[i,ii].imshow(_image)
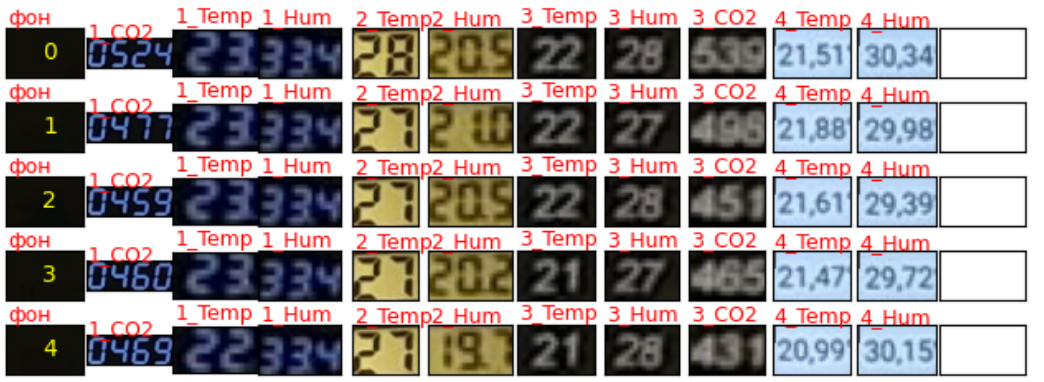
fig.savefig(f'co_2_{n_img}.png',bbox_inches='tight')[/code]Получим следующее изображение для 5 файлов:
![]()
На этом этапе, если значений немного, то можно их перенести вручную в таблицу для построения сравнительных графиков и оценки отклонений. Т.к. значения теперь рядом процесс перепечатывания упростится и ускорится, да и количество ошибок при вводе показаний сократится.
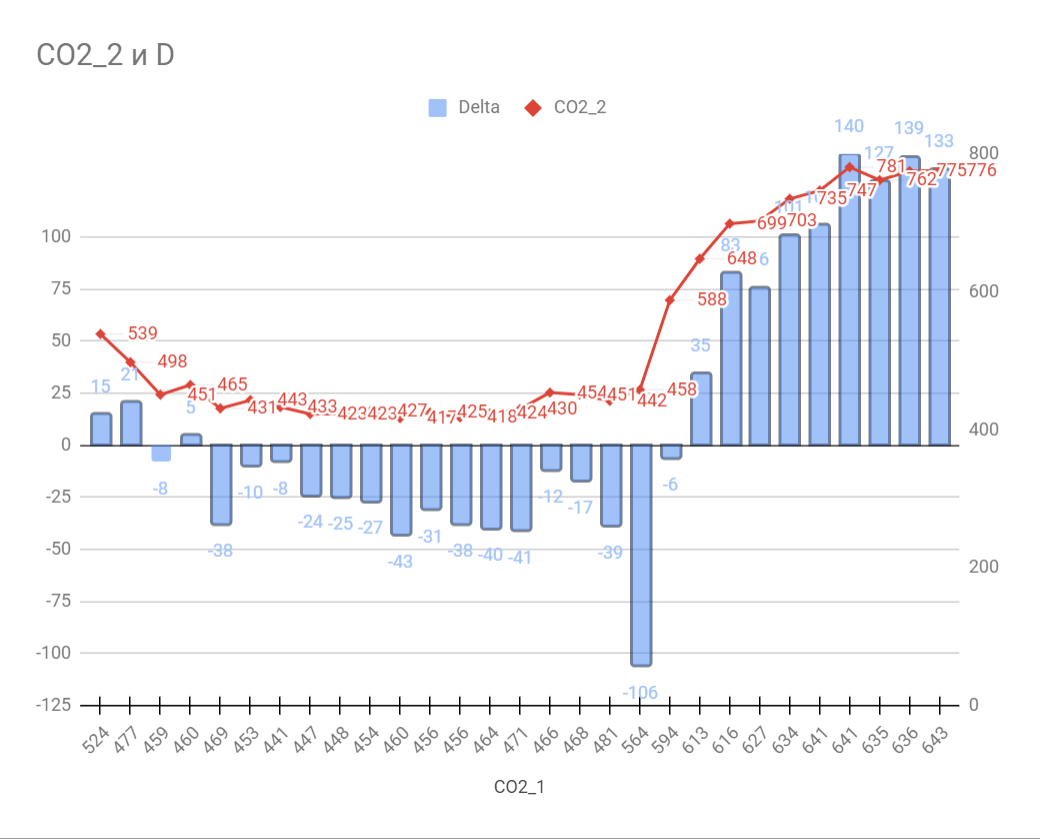
На основе таблицы можно построить графики и оценить корректировки по каждому из приборов, в частности, для индикаторов CO² получилась следующая картина.
![]()
С частичной автоматизацией ручного ввода разобрались. Теперь попробуем распознать значения индикаторов по изображениям.
Распознавание цифр на индикаторе
Задумка в следующем, т.к. цифровой индикатор состоит из 71 сегментов для отображения значений будем определять отличается ли изображение сегмента от области индикатора, где сегменты отсутствуют, т. е. фона.
1 сегментов может быть 8 или 9, если учитывать точку на индикаторах с поддержкой десятичных дробей или в экзотических случаях значков для отображения +/‑
Предварительно подбираем области индикаторных элементов и визуально проверяем наложение по 10 изображениям для каждой из цифр.
# Проверяем на отдельных цифрах
import glob
import pandas as pd
import numpy as df
from PIL import Image, ImageChops
from matplotlib.patches import Rectangle
# функция для определения отличается ли область сегмента индикатора от фона,
# подойдет любой другой вариант, чтобы понять активен сегмент или нет
def calcdiff(im1, im2):
dif = ImageChops.difference(im1, im2)
return np.mean(np.array(dif))
# этот колбэк не имеет практического заначения, используется только для красоты
def make_pretty(styler):
styler.background_gradient(axis=None, vmin=0, vmax=100, cmap="Blues")
return styler
# готовим изображения индикаторов для каждой цтфры
img_samples = glob.glob(r'numsamplercums*.png', recursive=True)
# задаем области сегментов индикатора
segs = [
[8,5,4,5], # фон индикатора
[1,6,4,4], # сегмент 1
[9,0,4,5], # сегмент 2
[14,6,4,4],
[13,16,4,4],
[7,22,4,5],
[1,16,4,4],
[8,11,4,5], # сегмент N
]
fig, axs = plt.subplots(ncols=len(img_samples), nrows=1, figsize=(15,4))
plt.setp(plt.gcf().get_axes(), xticks=[], yticks=[]);
plt.axis('off');
x,y,w,h = segs[0]
img_empty = Image.open(img_samples[0])
img_empty = np.array(img_empty)[y:y+h, x:x+w]
plt.imshow(img_empty)
num_segs_array = []
num_signature = {}
for i,im in enumerate(img_samples):
image_2=Image.open(im)
num_segs = []
img_num = Image.open(img_nums[i])
for ii, s in enumerate(segs):
x,y,w,h = s
axs[i].add_patch (Rectangle((x,y), w, h, edgecolor = '#f00', facecolor = 'blue', fill= False , lw= 1 ))
axs[i].text (x+1,y+3, ii, **{"color":"yellow"} )
if ii > 0:
im_cmp_1 = Image.fromarray(img_empty, 'RGB')
im_cmp_2 = Image.fromarray(np.array(img_num)[y:y+h, x:x+w])
num_segs += [int(f'{calcdiff(im_cmp_1, im_cmp_2):.0f}') ]
num_segs_array += [num_segs ]
# здесь можно задать уровень, по которому определяется активен сегмент или нет
num_signature["".join(['1' if int(n) > 50 else '0' for n in num_segs])] = i
axs[i].imshow(img_num)
df = pd.DataFrame(data=num_segs_array)
# выводим результат авторматической маркировки, собственно, эти сигнатуры можно было
# бы и просто описать указав 1 для активного сегмента, а 0 для не активного )
print (num_signature)
# визуализация сегментов индикатора (столбцы) для разных цифр (строки)
df.style.pipe(make_pretty) [/code]Зоны (segs) на индикаторе визуализируем для подбора оптимальных позиции и размеров областей сегментов.
![]()
В таблице уровни различий от фона для зон сегментов индикатора, определяемые ImageChops.difference(im1, im2). В нашем случае уровень от 0 до 100 не имеет значения, сигнатура для цифры определяется порогом в 50 и описывается 0 и 1, что определяет активен сегмент или нет для конкретной цифры.
![]()
Сигнатура для определения цифр выглядит следующим образом:
num_signature = {'1111110': 0,
'0011000': 1,
'0110111': 2,
'0111101': 3,
'1011001': 4,
'1101101': 5,
'1101111': 6,
'0111000': 7,
'1111111': 8,
'1111101': 9}Мы могли бы сигнатуру описать и без таблицы со уровнем отличия (от 0 до 100) сегментов от фона, но таблица дает определенную уверенность (порог между значениями 0/1 достаточно высокий), что распознавание будет надежным.
Проверка
Предварительно для тестирования потребуется нарезать в отдельную директорию большой массив изображений индикаторов, чтобы на случайной выборке проверять наш алгоритм.
# проверяем насколько у нас хорошо получилось на случайных изображениях
# функция для случайной выборки изображений индикатора
import random
def randImgs(sample_size=10, _mask=r"E:mpсо2202401312024.01.31_11.14.27*.jpg"):
glob_files = glob.glob(_mask, recursive=True)
sample_size = sample_size if sample_size <= len(glob_files) else len(glob_files)
_sample = [
glob_files[i]
for i in sorted(random.sample(range(len(glob_files)), sample_size))
]
return _sample
segs = [
[8, 5, 4, 5], # фон индикатора
[1, 6, 4, 4], # сегмент 1
[9, 0, 4, 5], # сегмент 2
[14, 6, 4, 4],
[13, 16, 4, 4],
[7, 22, 4, 5],
[1, 16, 4, 4],
[8, 11, 4, 5], # сегмент N
]
num_signature = {
"1111110": 0,
"0011000": 1,
"0110111": 2,
"0111101": 3,
"1011001": 4,
"1101101": 5,
"1101111": 6,
"0111000": 7,
"1111111": 8,
"1111101": 9,
}
def recoNum(img_path, segs):
x, y, w, h = segs[0]
_img = Image.open(img_path)
img_empty = np.array(_img)[y : y + h, x : x + w]
num_segs = []
for ii, s in enumerate(segs):
x, y, w, h = s
if ii > 0:
im_cmp_1 = Image.fromarray(img_empty, "RGB")
im_cmp_2 = Image.fromarray(np.array(_img)[y : y + h, x : x + w])
num_segs += [int(f"{calcdiff(im_cmp_1, im_cmp_2):.0f}")]
sig = "".join(["1" if int(n) > 50 else "0" for n in num_segs])
res = (
num_signature[sig] if sig in num_signature else "x"
) # x - если значения не найдено в num_signature
return res
sample_size = 180
colnum = 20
img_samples = randImgs(sample_size=sample_size, _mask=r"numsamplerc*.png")
results = []
fig, axs = plt.subplots(nrows=int(sample_size / colnum), ncols=colnum, figsize=(10, 8))
plt.setp(plt.gcf().get_axes(), xticks=[], yticks=[])
for i, img_path in enumerate(img_samples):
_n = str(recoNum(img_path, segs))
r = int(i / colnum)
c = i % colnum
axs[r, c].text(6, -1, _n, **{"size": 10, "color": "#f0f"})
axs[r, c].imshow(Image.open(img_path))
results += [_n][/code]В итоге получаем, что если изображения индикатора более менее соответствует образцовому изображению, то распознавание выполняется практически со 100% вероятностью. Для неполного изображения индикатора, камера или прибор поменяли положение во время съемки, то как правило, значение не определяется. В некоторых случаях возможны и ложные срабатывания (выделено красной рамкой) :
![]()
В случае с 8 понятно почему возникла ошибка, и чтобы ее исправить можно немного подумать и добавить одну строку в коде
Такой способ определения цифр по сегментам достаточно всеядный, т.к. определение активности сегментов индикатора выполняется путем сравнения с фоном, то есть контрастность, цвет, глубина цветовой палитры файла не оказывают существенного влияния.
Для распознавания по стандартной разметке потребуется преобразовать (поворот, масштабирование, наклон, перспектива) исходное изображение индикатора к более менее стандартному виду:
![]()
Но возможен вариант и без трансформации изображения. Для него потребуется разметку сегментов переопределить.
В первом и втором случаях преобразованы изображения под стандартную разметку сегментов, в третьем и четвертом задана индивидуальная разметка.
![]()
Заключение
Алгоритм может быть дополнен распознаванием значений для индикаторов с десятичным разделителем, или использоваться для других датчиков и даже аналоговых приборов. Например, достаточно будет добавить соответствующие зоны на шкале и проверять изменение цвета сегментов для распознавания значений индикатора:
![]()
шкала это просто ![]()
Совершенствование обработки изображений может быть продолжено с использованием библиотек автоматического определения местоположения индикаторов на снимке. Но это уже специальные алгоритмы, а в этой статье мы обходимся без ML, причем, вполне осознано. На эксперименты с tesseract было потрачено время, но результат разочаровал.
Потом была такая переписка (узнаете картинки?) из которой собственно и появилось решение и эта статья.
![]()
Возможно, стоит проверить, как будет работать алгоритм для цифр отображаемых шрифтами, если креативно задать области для сравнения, то можно получить вполне приемлемую достоверность распознавания.
Но эти задачи читатель может попробовать реализовать самостоятельно.
Если статья показалась вам полезной, поставьте, пожалуйста, соответствующую отметку.
Вопросы и ваши кейсы приветствуются в комментариях.
С уважением и успехов!

Обновление от февраля 2023 года статьи 2019 года с новыми мыслями. Думаю, что буду обновлять статью ежегодно, так как прогресс не стоит на месте.

Новинки Aqara: NFC-метки и новый цвет выключателя модели H1 - «Умный Дом»
15-апр-2024, 15:12
Обновление сервера: возможны временные потери связи - «Умный Дом»
25-ноя-2023, 10:40


Это не только возможность управлять лампочкой со смартфона, а слаженная, незаметная для Вас, работа всех систем дома как инструментов в оркестре.

В экосистему умного дома с Алисой интегрировали новое решение для борьбы с протечками воды от бренда NEPTUN. Система состоит из датчиков, хаба и

Теперь Станции с Алисой умеют подстраивать качество музыки под текущее интернет‑соединение. Если скорость интернета падает, устройство автоматически

На Станции Дуо Макс появилась поддержка видеозвонков — в магазине приложений теперь доступно приложение «Телемост». Оно использует встроенную камеру

Яндекс совместно с брендом NEPTUN выпустили систему защиты от протечек, которая интегрирована с умным домом Яндекса. В случае аварии она

Яндекс совместно с брендом NEPTUN представили систему защиты от протечек, интегрированную с умным домом Яндекса. Решение помогает минимизировать

Яндекс представил комплексное решение с Алисой для отелей. Оно объединяет Станции и устройства умного дома, которые можно установить в номерах, софт