Станция Миди и голосовое управление Zigbee-устройствами без интернета. История разработки
- Admin-katalogaptek
- 25-ноя-2023, 08:48
- 0 комментариев
- 2 540 просмотров


Недавно мы представили нашу новую умную колонку — Яндекс Станцию Миди. Она больше, чем Лайт или Мини, поэтому в ней уместились вуфер и два высокочастотных динамика с суммарной мощностью звука 24 Вт. Но при этом она легче и компактнее, чем Станция 2 или Макс. Кроме того, в Миди мы внедрили технологии, которые позволили Алисе научиться новому. В частности, благодаря более современному процессору и бо́льшему объёму оперативной памяти, Алиса в Станции Миди впервые стала понимать и выполнять голосовые команды умного дома локально, без интернета.
Сегодня коротко расскажем, какие задачи пришлось решить команде Алисы и умных устройств, чтобы у пользователей появилась возможность управлять Zigbee-совместимыми устройствами с помощью голоса и не зависеть при этом от удалённого сервера или провайдера.
Что важно: это полезно не только при проблемах со связью. Теперь Zigbee-устройства будут реагировать на команды быстрее даже при наличии хорошего интернета (чуть подробнее — в блоке про замеры скорости в конце поста).
Про локальный умный дом мы впервые заговорили весной этого года. Возможно, вы даже читали на Хабре статью о том, как мы научили наши колонки со встроенным Zigbee-модулем хранить и выполнять сценарии умного дома напрямую, без посредника в виде сервера. Но были ограничения: это работало только для тех сценариев, которые запускались по кнопке или таймеру. Потому что работа с голосовыми командами была доступна только через наше облако. Слишком уж тяжеловесной была это задача для железа.
Вернёмся к новой Станции Миди. Возможно, когда-нибудь мы расскажем о том, как нам удалось уместить кастомную акустику, LED-подсветку, дисплей и всю остальную электронику в относительно компактный корпус, но сегодня нас интересует другое — новый вычислительный блок, а точнее, SoC A113X2 от Amlogic с выделенным NPU, а также 1 GB оперативной памяти и 8 GB флеш-памяти (для сравнения: в Мини — 256 MB RAM и 256 MB флеш-памяти). Неплохой запас вычислительных ресурсов для такого класса устройств. Без него у нас не получилось бы реализовать задуманное. Но одних лишь ресурсов было мало. Нам нужно было перепридумать то, что создавалось для работы на сервере.
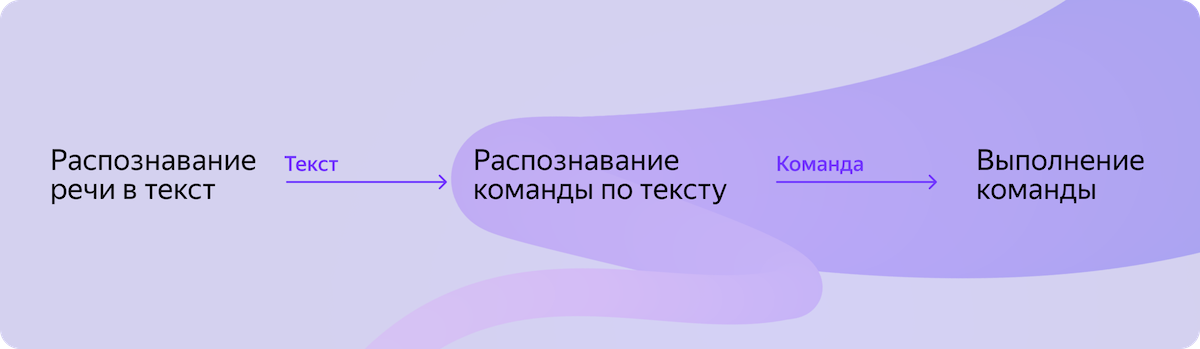
Изначально процесс работы с умным домом был частью процесса Алисы в облаке. Но чтобы добиться локальности, нам нужно было аккуратно вынести три последовательных компонента, отвечающих за умный дом, в отдельный пайплайн на устройстве. И при этом ничего не сломать в облачных сценариях. На схеме ниже вы можете увидеть компоненты, которые должны были заработать локально.
И всё бы хорошо, но был нюанс. Ни одного из этих готовых для применения на устройстве компонентов у нас не существовало в прошлом. А значит, их нужно было создать.
Самое очевидное: нам нужна нейросеть, которая будет распознавать голос в текст прямо на устройстве. С хорошим качеством. И при этом работать не на самом мощном суперкомпьютере в России, а на маленькой SoC, которая делит весьма ограниченную жилплощадь с другими полезными вещами. Ничего сложного, да?
Для начала расскажем, как работает наш облачный ASR. Если упростить, то это три нейросети. Первая на лету превращает поток в слова, не дожидаясь завершения всей фразы. Это полезно, чтобы пользователи могли сразу видеть в интерфейсе свой запрос по мере того, как они его произносят. Поэтому эта нейросеть быстрая и относительно лёгкая по серверным меркам (всего-то каких-то пару сотен миллионов параметров).
В паре с первой нейросетью работает вторая, единственная задача которой — предсказывать момент завершения фразы.
Когда реплика закончилась, вся фраза целиком отправляется на вход самой большой, третьей нейросети. Она работает медленнее, но и качество распознавания произвольных фраз выше. И именно результат работы третьей нейросети считается финалом.
Но колонка — это не кластер со множеством GPU. Мы не можем себе позволить уместить в неё несколько серверных моделей. Даже одну не можем. Начали думать, где можем сэкономить ресурсы. Описанная выше первая нейросеть из серверного решения, хоть и расшифровывает каждое слово на лету, в действительности работает не в режиме стриминга, а заново расшифровывает всю фразу целиком после появления нового звука (возможно, вы замечали при обращении к Алисе, что текст запроса может измениться задним числом). Это сделано специально. Каждое новое распознанное слово может помочь нейросети уточнить распознавание предыдущих слов за счёт контекста диалога. Например, слово «бить» может распознаться как «пить» из-за шумов в фоне. Но если последующее слово будет распознано как «баклуши», то это даст возможность уточнить, что предыдущее слово всё-таки было «бить».
Однако такой режим работы потребляет очень много ресурсов, ведь каждый новый звук, по сути, перезапускает работу модели. Если перейти в честный стриминг (распознавание на лету с учётом прошлого, но без учёта будущего), то можно сэкономить. Да, модель при этом будет работать на несколько процентов хуже, но это вполне допустимо для нашей задачи (с учётом дефицита ресурсов и фокуса на запросах только из области умного дома).
Мы провели тесты с учётом перехода работы в режим стриминга. Для нас было важно, чтобы модель не просто работала на колонке, но и распознавала речь в текст так же быстро, как человек произносит её. Посчитали, что оптимально ориентироваться на модель с примерно десятком миллионов параметров. Причём нам нужна была именно единая модель, которая будет и расшифровывать текст, и предсказывать конец фразы.
Несколько слов об архитектуре для тех, кому интересно. Наша быстрая серверная нейросеть основана на подходе CTC. Сам по себе этот подход вполне совместим со стримингом, но на качество результата больше всего влияет энкодер (та часть нейросети, которая на входе преобразует речь в векторное представление). Мы выбрали энкодер с архитектурой трансформера — по нашему опыту, лучший вариант на текущий момент. Но CTC в связке с трансформером в режиме стриминга проседал в качестве. Поэтому мы приняли решение заменить CTC на RNN-T. Этот подход в связке с тем же трансформером в режиме стриминга показал более высокое качество распознавание речи.
С размером модели разобрались. С архитектурой тоже. Теперь коротко про датасет. Обучение модели происходит в облаке, а там таких проблем с вычислительными ресурсами нет. Мы воспользовались датасетом, на котором обучаем облачные модели ASR. Но с рядом изменений. Главное из которых заключается в том, что мы добавили к нему дополнительные примеры из области работы с умным домом. Так мы «показали» нейросети, что именно этот срез запросов нам особенно важен. При этом другие качественные, оригинальные примеры мы не вырезали из датасета, потому что общее разнообразие данных тоже влияет на качество.
В итоге мы получили нейросеть, которая помещалась на устройстве и могла в реальном времени превращать речь в текст в автономном режиме.
Итак, у нас есть текст речи пользователя. Теперь нужно распознать в нём команду умного дома. С учётом всего многообразия таких команд. С пониманием имён сценариев, которые могут быть произвольными, так как пользователь сам их придумывает. И с хорошей точностью, потому что, помимо команд умного дома, существуют и другие сценарии, для корректной работы которых запрос надо отправить в облако. Можно сказать, классическая NLU-задачка.
Яндекс уже давно умеет решать подобные задачки в Поиске, Алисе и многих других сервисах. Например, коллеги из поисковой инфраструктуры разработали Бегемота (Begemot) — сервис, который помогает понимать запросы и превращать неструктурированный текст в понятные для дальнейшей обработки структуры. Хорошая новость в том, что этот сервис работает быстро, так как создавался для Поиска. Но есть плохая (для нас): работает эта штука на инфраструктуре компании. Одна инсталляция потребляет не менее 30 GB RAM и ещё около 30 GB флеш-памяти. Запустить такое на Станции Миди шансов просто не было. Нужно было адаптировать.
Если всё сильно упростить, то Бегемот — это много-много компонентов, которые образуют граф обработки запроса пользователя. Например, это могут быть компоненты, которые помогают находить в тексте географические объекты. Или даты. Или команды Алисы. Поэтому самый очевидный вариант — посадить его на диету: отказаться от всех компонентов, которые не требуются при работе с умным домом. Но рефакторинг кода всё же понадобился, чтобы отказаться от невостребованных нами зависимостей, граф которых тоже надо было детально изучить. В том числе мы отказались от компонентов, которые были предназначены для работы с ML: команды умного дома простые и структурированные, тяжёлый ML нам тут просто не нужен. Ещё был риск, что потребуется что-то специально переписать под ARM, но — к счастью! — этот риск не реализовался.
В итоге мы собрали свою версию, которая уместилась в 90 MB RAM и 73 MB флеш-памяти (иногда ласково называем её Бегемотиком).
Теперь у нас есть команда умного дома в машиночитаемой форме. Команды бывают очень разные. А ещё бэкенд умного дома должен корректно отрабатывать переименование устройств, поддержку разных комнат и домов и многое-многое другое. Всю эту логику для Миди можно было бы написать с нуля на C++. Но, во-первых, это долго, а, во-вторых, синхронизировать изменения функциональности между локальным и облачным компонентами сложнее, если они созданы независимо.
Был и альтернативный путь: собрать более лёгкую версию бэкенда умного дома. В этом случае конфигурацию умного дома пользователя можно было бы хранить на устройстве и синхронизировать с облаком в одном и том же формате. Звучало красиво, вот только бэкенд написан на Go и потребляет больше полгига флеш-памяти и под 200 мегабайт оперативной. Но идея нам понравилась, поэтому начали думать.
Go — язык компилируемый, под ARM собирается. Ситуация проще, чем могла бы быть с Java или Python. Попробовали собрать бинарник и запустить на платформе. Запустился. Дальше оставалось поработать над его аппетитами. Как и в истории про Бегемота, начали руками отбрасывать всё, что не требуется хранить локально на колонке. Например, отказались от компонента, который отвечает за озвучивание колонкой показаний датчиков, потому что локального синтеза речи у нас всё равно нет. В итоге бинарник стал легче и быстрее (уложился в 90 MB оперативки) и благополучно заработал на Станции.
На Станции Миди нам удалось завести не просто локальный умный дом с поддержкой Zigbee-устройств, но и дать людям возможность управлять им голосом. Это полезно не только при отсутствии интернета. Локальный процесс работает для команд умного дома всегда, а значит, ваша Zigbee-лампочка и любое другое совместимое устройство будут включаться быстрее.
Ускорение мы замерили так: в одних тестовых колонках включили принудительно облачный процесс работы с умным домом, в других — локальный, а затем прогнали десятки команд и подсчитали тайминги. Скорость ASR во многом зависит от сложности фразы, которую надо распознать. Поэтому разброс результатов большой. Но в среднем локальный ASR отработал быстрее, хоть и не в разы. А вот с остальными этапами процесса всё куда нагляднее: локальные Бегемотик и бэкенд УД справились с задачами в среднем в 6 раз быстрее, чем вариант с облаком (в том числе за счёт отсутствия сетевых задержек).
Следующий этап — дождаться отзывов первых пользователей Станции Миди, которые будут использовать её для управления Zigbee-устройствами. Хочется верить, что пользователи заметят разницу на глаз и подтвердят востребованность нового решения. А что думаете вы?

Компания Samsung объявила о том, что ее платформа для умного дома SmartThings теперь поддерживает Matter 1.5. Это обеспечивает совместимость с

Новинки Aqara: NFC-метки и новый цвет выключателя модели H1 - «Умный Дом»
15-апр-2024, 15:12
Обновление сервера: возможны временные потери связи - «Умный Дом»
25-ноя-2023, 10:40


Это не только возможность управлять лампочкой со смартфона, а слаженная, незаметная для Вас, работа всех систем дома как инструментов в оркестре.

Компания Flipper, известная своими инструментами для беспроводного тестирования и пентестинга, анонсировала BUSY Bar - открытый «мультитул

В экосистему умного дома с Алисой интегрировали новое решение для борьбы с протечками воды от бренда NEPTUN. Система состоит из датчиков, хаба и

Теперь Станции с Алисой умеют подстраивать качество музыки под текущее интернет‑соединение. Если скорость интернета падает, устройство автоматически

На Станции Дуо Макс появилась поддержка видеозвонков — в магазине приложений теперь доступно приложение «Телемост». Оно использует встроенную камеру

Яндекс совместно с брендом NEPTUN выпустили систему защиты от протечек, которая интегрирована с умным домом Яндекса. В случае аварии она

Яндекс совместно с брендом NEPTUN представили систему защиты от протечек, интегрированную с умным домом Яндекса. Решение помогает минимизировать