Бизнесу теперь доступен сервис Сбера для проверки и корректуры текстов с помощью технологий искусственного интеллекта - «Умный Дом и решения»
- Федосий
- 06-окт-2023, 11:27
- 0 комментариев
- 2 394 просмотров

Новый ИИ-сервис представляет собой инструмент для проверки орфографии в текстах на русском языке, работающий на основе нейросетевой генеративной модели. Решение может быть использовано бизнесом для корректуры текста любой длины и формата — в копирайтинге и редактуре, при создании маркетинговых и рекламных материалов, в работе редакций СМИ. Сервис разработан компанией SberDevices и доступен в каталоге AI Services на платформе ML Space для зарегистрированных пользователей.Новый ИИ-сервис представляет собой инструмент для проверки орфографии в текстах на русском языке, работающий на основе нейросетевой генеративной модели. Решение может быть использовано бизнесом для корректуры текста любой длины и формата — в копирайтинге и редактуре, при создании маркетинговых и рекламных материалов, в работе редакций СМИ. Сервис разработан компанией SberDevices и доступен в каталоге AI Services на платформе ML Space для зарегистрированных пользователей.
«Современные модели на основе искусственного интеллекта предоставляют всё больше возможностей для текстовой редактуры. С помощью представленного решения можно обработать любой текст, переписав его без ошибок, использовать генеративные возможности моделей для коррекции правописания в текстах различных доменов. Инструмент может стать ИИ-помощником в различных информационных проектах и поможет быстро и качественно исключить орфографические ошибки в текстах, сэкономив время и ресурсы».
Денис Филипповвице-президент по цифровым поверхностям «Салют» СбербанкаПеред командой разработчиков стояла задача изучить и решить проблемы корректуры правописания с помощью генеративных моделей. Результатом стала разработанная методология генеративной коррекции орфографии для русского языка, которая показывает качество уровня SOTA на задаче проверки орфографии. По итогам работы выпущены: библиотека SAGE с открытым исходным кодом (лицензия MIT), семейство предобученных генеративных моделей (ruM2M100-1.2B, ruM2M100-418M, FredT5-large-spell, T5-large-spell) для корректуры правописания на русском и английском языках и хаб с размеченными данными для задачи коррекции орфографии в текстах разных доменов.
На данный момент представленный инструмент опережает по качеству открытые решения для русского языка и проприетарные модели конкурентов. Существенный прирост в метриках относительно других решений является следствием разработанной методологии. Было предложено два метода аугментации ошибок для воспроизведения естественных человеческих опечаток и орфографических ошибок в текстах. С помощью этих модулей был создан корпус текстов с ошибками (около 7 Гб), на котором обучались генеративные модели M2M100 и FredT5-large. Второй этап заключался в дообучении моделей на комбинации собранных параллельных датасетов для исправления орфографии. Лучшая конфигурация полученного решения представлена в виде AI-сервиса на платформе ML Space.

Сбер запускает ТВ-медиацентр с умной камерой SberBox Top: видеозвонки, игры и дополненная реальность — в вашем телевизоре 20 мая 2021. Одним из

Новинки Aqara: NFC-метки и новый цвет выключателя модели H1 - «Умный Дом»
15-апр-2024, 15:12
Обновление сервера: возможны временные потери связи - «Умный Дом»
25-ноя-2023, 10:40


Это не только возможность управлять лампочкой со смартфона, а слаженная, незаметная для Вас, работа всех систем дома как инструментов в оркестре.

Компания Яндекс представила датчик присутствия для умного дома. Устройство поддерживает автоматизации на основе присутствия человека в

Яндекс представил ещё одно устройство для умного дома — датчик присутствия. Он определяет не только движение, но и наличие и местонахождение людей в

Компания Aqara начала продажи серии умных замков U500 в Великобритании. Линейка включает модели Smart Gate Lock U500, Smart Glass Door Lock U500 и
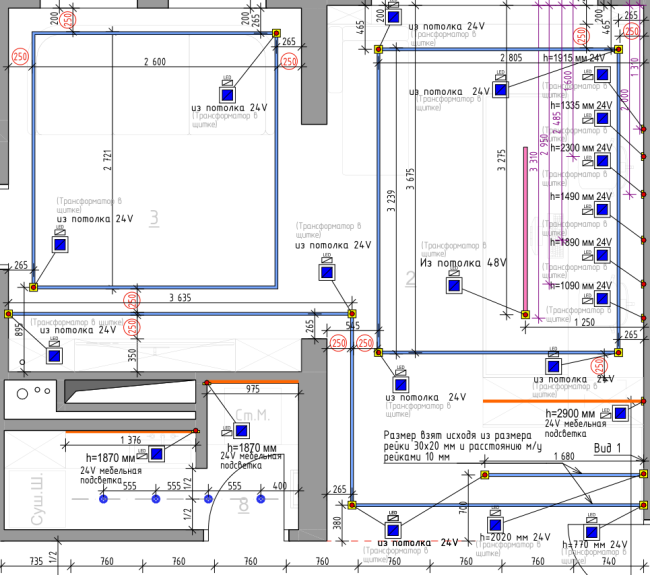
Расскажу о том, что мне важно увидеть в дизайн-проекте, чтобы у меня не было вопросов к дизайнеру. Эти моменты касаются элементов электрики:

Компания Govee анонсировала систему фоновой подсветки для телевизоров - TV Backlight 3. Устройство поддерживает Matter и синхронизирует подсветку с

Наконец произошло то, чего я достаточно долго ждал — в ассортименте бренда Netcraze (ранее — Keenetic) появилась уличная Wi-Fi точка доступа.