Открыт доступ к модели генерации текста для русского языка ruGPT-3.5 и расширенной версии нейросети mGPT, способной генерировать тексты на 61 языке - «Умный Дом и решения»
- Marshman
- 20-июл-2023, 11:30
- 0 комментариев
- 2 446 просмотров

Сбер открыл доступ к нейросетевой модели ruGPT-3.5 13B. Её дообученная версия лежит в основе сервиса GigaChat. Также банк выложил новую версию модели mGPT 13B — самой большой из семейства многоязычных моделей Сбера.
ruGPT-3.5
Внутри GigaChat находится целый ансамбль моделей — NeONKA (NEural Omnimodal Network with Knowledge-Awareness). Для его создания нужно было выбрать базовую языковую модель, которую потом можно было обучать на инструктивных данных. Russian Generative Pretrained Transformer версии 3.5 с 13 млрд параметров (ruGPT-3,5 13B) — новая версия нейросети ruGPT-3 13B.
Это современная модель генерации текста для русского языка на основе доработанной исследователями Сбера архитектуры GPT-3 от OpenAI. Модель ruGPT-3,5 13B содержит 13 миллиардов параметров и умеет продолжать тексты на русском и английском языках, а также на языках программирования. Длина контекста модели составляет 2048 токенов. Она обучена на текстовом корпусе размером около 1 Тб, в который, помимо уже использованной для обучения ruGPT-3 большой коллекции текстовых данных из открытых источников, вошли: юридические документы, часть The Stack (открытый сет с кодом) от коллаборации исследователей BigCode и корпуса новостных текстов. Финальный чекпоинт модели — это базовый претрейн для дальнейших экспериментов.
В обучении модели участвовали команды SberDevices и Sber AI при поддержке Института искусственного интеллекта AIRI.
mGPT
Также в открытом доступе опубликована многоязычная модель mGPT-13B под открытой лицензией MIT. Версия mGPT 13B содержит 13 млрд параметров и способна продолжать тексты на 61 языке, включая языки стран СНГ и малых народов России. Длина контекста модели составляет 512 токенов. Она была обучена на 600 Гб текстов на разных языках, собранных из очищенных и подготовленных датасетов multilingual C4 и других открытых источников.
Модель может использоваться для генерации текста, решения различных задач в области обработки естественного языка на одном из поддерживаемых языков путём дообучения или в составе ансамблей моделей.
Сбер, как ведущая технологическая компания, выступает за открытость технологий и обмен опытом с профессиональным сообществом, ведь любые разработки и исследования имеют ограниченный потенциал в замкнутой среде. Поэтому мы уверены, что публикация обученных моделей подстегнёт работу российских исследователей и разработчиков, нуждающихся в сверхмощных языковых моделях, создавать на их базе собственные технологические продукты и решения. Пробуйте, экспериментируйте и обязательно делитесь полученными результатами.
Андрей Белевцевстарший вице-президент, CTO, руководитель блока «Технологии» Сбербанка
Сбер запускает ТВ-медиацентр с умной камерой SberBox Top: видеозвонки, игры и дополненная реальность — в вашем телевизоре 20 мая 2021. Одним из

Новинки Aqara: NFC-метки и новый цвет выключателя модели H1 - «Умный Дом»
15-апр-2024, 15:12
Обновление сервера: возможны временные потери связи - «Умный Дом»
25-ноя-2023, 10:40


Это не только возможность управлять лампочкой со смартфона, а слаженная, незаметная для Вас, работа всех систем дома как инструментов в оркестре.

Компания Яндекс представила датчик присутствия для умного дома. Устройство поддерживает автоматизации на основе присутствия человека в

Яндекс представил ещё одно устройство для умного дома — датчик присутствия. Он определяет не только движение, но и наличие и местонахождение людей в

Компания Aqara начала продажи серии умных замков U500 в Великобритании. Линейка включает модели Smart Gate Lock U500, Smart Glass Door Lock U500 и
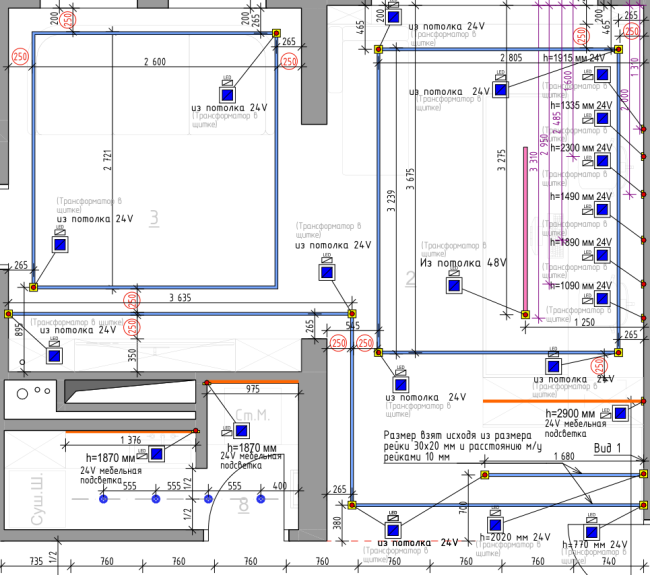
Расскажу о том, что мне важно увидеть в дизайн-проекте, чтобы у меня не было вопросов к дизайнеру. Эти моменты касаются элементов электрики:

Компания Govee анонсировала систему фоновой подсветки для телевизоров - TV Backlight 3. Устройство поддерживает Matter и синхронизирует подсветку с

Наконец произошло то, чего я достаточно долго ждал — в ассортименте бренда Netcraze (ранее — Keenetic) появилась уличная Wi-Fi точка доступа.